
 欢迎来到
欢迎来到
故障演练
定义
编辑
故障演练是可用性的一种测试方法,其中可用性是GB25010定义的八大质量特性可靠性下的子特性,常用在固定周期内系统可对外提供服务的时间来表示。故障演练就是模拟出现故障能够尽快恢复的一种集技术、方法、策略于一体的验证方法。一次完整的故障演练由演练的对象、对象发生的具体故障、应用的预期故障应对表现、对应用表现的实际观察和判断几部分组成。
实践出处
编辑
故障演练以及可用性定义分别来自《持续测试》这本书和GB25010
为什么
编辑
为了保证系统的稳定,测试工程师可谓想尽了办法,除了常规的测试以外,还会通过在测试过程中创造一些故障,来验证系统的一些可靠性保障机制是否有效。
何时使用
编辑
系统的可用性问题突出,功能性、性能效率等质量特性已经得到了有效保障后。
如何使用
编辑
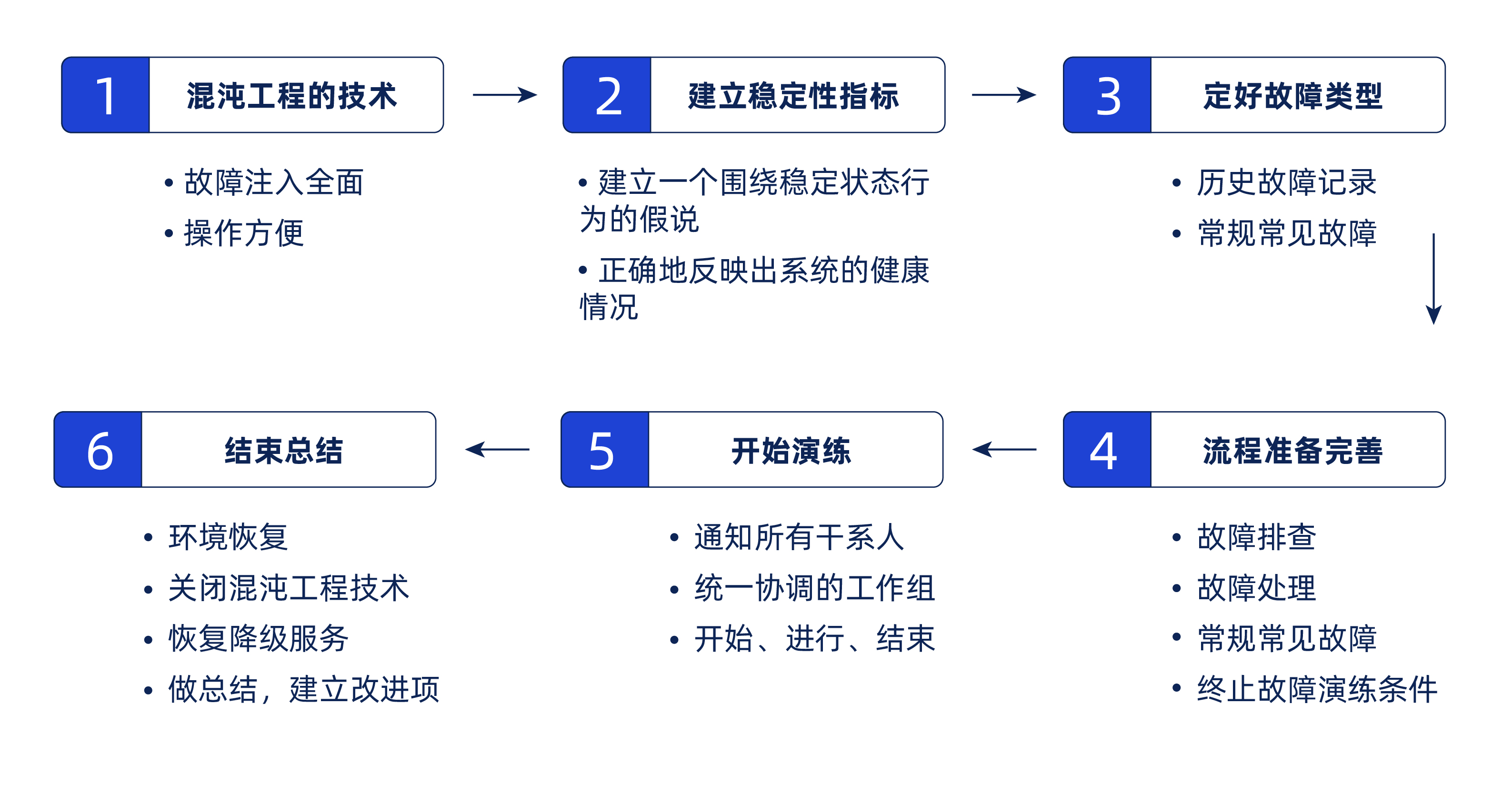
故障演练的技术层面比较常用的就是混沌工程,是混沌工程的具体实践,通过向目标系统注入真实可能发生的故障来考量系统的稳定。混沌工程为稳定性验证实验提供可实践的指导,可见如果要将混沌工程落地实践最基础的就是要有一个快速、方便的故障注入工具,然后再结合混沌工程的理论进行故障演练,从而提高系统的稳定性。
-
选好混沌工程的工具
工欲善其事必先利其器,选取一个好的混沌工程的工具会对测试工程师来说可谓是工作事半功倍。开源的混沌工程的工具有很多,站在团队的角度选取的工具要是平台化的,作为故障演练的统一入口,需要提供方便、易用的交互方式,能够自动完成故障注入。提供多样化、可视化操作的故障注入自动化平台,作为各种演练和故障测试及验证的统一入口。通过故障注入平台能够帮助业务发现更多未知的影响业务稳定的问题,验证业务的告警有效性和完整性,以及业务的故障预案是否有效。作者比较推荐的是阿里巴巴开源的ChaosBlade,ChaosBlade内置的场景非常多,它不仅仅只能模拟CPU满载、磁盘IO过高等简单故障,还可以模拟Dubbo调用超时、杀容器、杀pod等,从而我们可以制造更多的实验场景,并且ChaosBlade方便易用,还可以自行扩展场景。
-
建立稳定性指标
既然故障演练就是混沌工程的一次实践,那么所有的演练都必然就要站在混沌工程“建立一个围绕稳定状态行为的假说”的原则基础之上开始设计,因此需要在开始之前定义好故障演练过程中需要监控的指标,这些指标可以正确地反映出系统的健康情况,并在出现问题的时候可以直接通过指标表现出来,也能知道对应的指标表现可能造成的结果,帮助触发监控预警,以便快速的解决问题。
-
定好故障类型
故障演练中触发的故障并不是随意选取的故障,而是通过对系统历史上出现的问题,以及类似系统出现过的问题的一次总结和归纳。常规用到比较多的故障有外部依赖超时访问,kafka超时,kafka不可用,数据可不可用,CPU满载,网络中断,服务器宕机、磁盘没空间等。
-
流程准备
除去上面的一些故障相关准备以外,在开始故障演练前还要检查的流程准备是不是已经完善了,例如故障决策链是不是清晰明确,各种故障是否都有明确的故障排查和解决方案,每种方案是不是都确实可行。
-
开始演练
通知所有相关干系人,这里面包含了相关业务的开发工程师、业务工程师还有就是基础设施工程。通知内容包含参与故障演练的服务、故障演练的开始实践、故障演练的结束实践、故障演练对应服务的所在集群环境,建立统一协调的工作组即时聊天群。通过故障注入工具将问题注入到系统中,观察故障排查和解决的全过程,重点记录信息如下:
● 故障有无按照预期被修复或者降低影响
● 业务指标的变化
● 稳定性指标变化
● 如果有降级处理,对应降级方案是否生效
在故障演练过程中,如果出现任何超出控制或者超出原定计划的故障影响范围,都要马上终止故障演练,快速恢复系统,同时要清理全部故障演练对系统的影响和痕迹,因为故障演练实在真是环境中进行的,除去测试的业务之外,还有很多真实用户在使用系统,不能因为要完成故障演练而因此真是故障。
-
结束总结
重点中的重点是恢复故障演练的环节,故障演练都是在真实环境中完成的,因此一定要记住恢复全部环境,关闭故障注入工具,恢复降级处理的服务,以保证服务可以恢复到故障演练之前的正常状态。然后对过程做总结和,并且针对问题整改计划。
输出物
编辑
故障演练总结报告
参考资料
编辑
-
《混沌工程:复杂系统韧性实现之道》[美] 凯西·罗森塔尔(Casey Rosenthal)著,吾真本、黄帅 译,机械工业出版社
-
《持续测试》陈磊著,人民邮电出版社
我们非常重视知识产权,我们在非常努力地寻找最初的出处来源并注明出处。但因为互联网信息浩瀚,难免会有疏漏。如果您觉得有侵犯您的权益,请联系我们。
分享





